TiDB云原生數(shù)據(jù)庫 技術(shù)架構(gòu)與數(shù)據(jù)處理開發(fā)實踐
在當今數(shù)據(jù)驅(qū)動的時代,企業(yè)對于數(shù)據(jù)處理技術(shù)的需求正朝著高并發(fā)、高可用、強一致性與彈性擴展的方向飛速發(fā)展。傳統(tǒng)的單機數(shù)據(jù)庫或主從架構(gòu)在面對海量數(shù)據(jù)與復(fù)雜業(yè)務(wù)場景時,往往力不從心。TiDB,作為一款開源的分布式NewSQL數(shù)據(jù)庫,憑借其云原生設(shè)計理念和與MySQL高度兼容的特性,成為了構(gòu)建現(xiàn)代數(shù)據(jù)平臺的明星選擇。本文將從其核心架構(gòu)出發(fā),探討在數(shù)據(jù)處理技術(shù)開發(fā)中的實踐應(yīng)用。
一、TiDB核心技術(shù)架構(gòu)解析
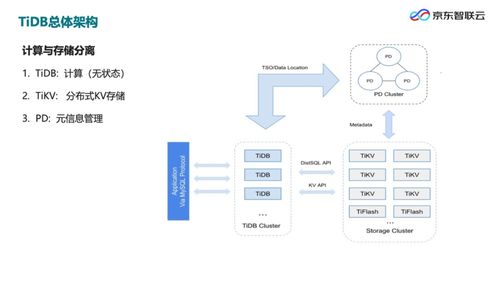
TiDB的整體架構(gòu)清晰地將計算與存儲分離,主要由三個核心組件構(gòu)成:
- TiDB Server(計算層):
- 角色:無狀態(tài)的SQL層,負責(zé)接收客戶端連接、解析SQL、優(yōu)化查詢計劃、生成分布式執(zhí)行計劃。
- 特點:完全兼容MySQL協(xié)議和語法,應(yīng)用可近乎無縫遷移。其無狀態(tài)設(shè)計便于水平擴展,通過負載均衡器即可輕松應(yīng)對流量高峰。
- TiKV Server(存儲層):
- 角色:分布式、支持事務(wù)的鍵值存儲引擎,是數(shù)據(jù)持久化的核心。
- 核心技術(shù):
- Raft共識協(xié)議:確保數(shù)據(jù)在多副本間強一致、高可用。每個數(shù)據(jù)Region(默認96MB~144MB)都是一個Raft Group。
- Multi-Raft:將整個數(shù)據(jù)集劃分為眾多Region,并發(fā)運行大量Raft組,極大提升了并行處理能力和吞吐量。
- 分布式事務(wù):采用兩階段提交(2PC)與樂觀鎖模型,并內(nèi)置了時間戳授時器(PD),提供快照隔離(SI)和讀已提交(RC)隔離級別。
- Placement Driver (PD)(調(diào)度與元管理層):
- 角色:集群的“大腦”,負責(zé)全局元數(shù)據(jù)管理、TiKV節(jié)點與數(shù)據(jù)Region的調(diào)度、以及全局時間戳的分配。
- 功能:通過持續(xù)監(jiān)控集群狀態(tài),自動進行負載均衡、故障恢復(fù)(如Leader重選、副本補全)、熱點Region調(diào)度等,確保集群始終處于最優(yōu)工作狀態(tài)。
TiFlash作為列式存儲引擎,通過Raft Learner協(xié)議異步從TiKV復(fù)制數(shù)據(jù),與行存引擎TiKV形成HTAP(混合事務(wù)/分析處理)架構(gòu),使得一套系統(tǒng)既能高效處理在線事務(wù),也能進行實時數(shù)據(jù)分析,避免了復(fù)雜的ETL過程。
二、在數(shù)據(jù)處理技術(shù)開發(fā)中的核心實踐
基于上述架構(gòu),開發(fā)者在構(gòu)建數(shù)據(jù)處理系統(tǒng)時可以獲得諸多優(yōu)勢與實踐啟發(fā):
1. 彈性伸縮,應(yīng)對業(yè)務(wù)增長
- 實踐:在業(yè)務(wù)快速增長或存在明顯波峰波谷(如電商大促)的場景下,可根據(jù)需求動態(tài)增刪TiDB Server(計算節(jié)點)和TiKV Server(存儲節(jié)點)。PD會自動將數(shù)據(jù)和負載重新調(diào)度到新節(jié)點上,整個過程對應(yīng)用透明。這為容量規(guī)劃與成本控制提供了極大的靈活性。
2. 高可用與容災(zāi)設(shè)計
- 實踐:TiDB默認采用多副本(通常為3副本)存儲。任何單個節(jié)點、甚至整個可用區(qū)(AZ)的故障,都不會導(dǎo)致數(shù)據(jù)丟失或服務(wù)長時間中斷。Raft協(xié)議能快速選舉出新Leader,PD會調(diào)度新副本以維持復(fù)制因子。開發(fā)者可以基于此,輕松構(gòu)建同城多活或異地災(zāi)備方案,將容災(zāi)能力從數(shù)據(jù)庫層面提升到架構(gòu)層面。
3. 簡化復(fù)雜事務(wù)處理
- 實踐:對于需要跨多個分片(或傳統(tǒng)分庫分表中間件中多個表)的復(fù)雜事務(wù),TiDB提供了原生的分布式事務(wù)支持。開發(fā)者無需再在應(yīng)用層小心翼翼地處理分布式事務(wù)的補償邏輯(如Saga模式),可以像使用單機MySQL一樣使用
BEGIN、COMMIT,極大降低了業(yè)務(wù)開發(fā)的復(fù)雜度與出錯概率。
4. 實現(xiàn)實時HTAP分析
- 實踐:在數(shù)據(jù)倉庫/OLAP場景中,傳統(tǒng)鏈路是T+1地將OLTP數(shù)據(jù)同步到分析型數(shù)據(jù)庫。借助TiFlash,開發(fā)者可以:
- 為需要分析的TiDB表創(chuàng)建列存副本(ALTER TABLE ... SET TIFLASH REPLICA ...)。
- 在SQL中通過優(yōu)化器提示(如/+ read_from_storage(tiflash[table_name]) /)或由TiDB智能選擇,讓分析查詢直接路由到TiFlash執(zhí)行,獲得極致的列存分析性能。
- 這意味著訂單分析、實時報表、風(fēng)控查詢等業(yè)務(wù)可以運行在最新的數(shù)據(jù)上,實現(xiàn)真正的實時決策。
5. 與大數(shù)據(jù)生態(tài)無縫集成
- 實踐:TiDB提供了豐富的數(shù)據(jù)導(dǎo)入導(dǎo)出工具(如Dumpling, TiDB Lightning)以及與Apache Spark的直接集成(TiSpark)。這使得它能夠:
- 作為海量歷史數(shù)據(jù)的統(tǒng)一存儲和查詢?nèi)肟凇?/li>
- 方便地將數(shù)據(jù)批量同步到Hadoop或數(shù)據(jù)湖中進行深度挖掘。
- 利用Spark的強大算力,在TiKV/TiFlash上執(zhí)行更復(fù)雜的分布式機器學(xué)習(xí)或ETL任務(wù)。
三、開發(fā)注意事項與最佳實踐
- Schema設(shè)計:雖然兼容MySQL,但為發(fā)揮分布式優(yōu)勢,表應(yīng)有明確的主鍵(最好具有單調(diào)遞增屬性以避免熱點),并合理使用聚簇索引。避免超寬表,關(guān)注熱點Region的分布。
- SQL優(yōu)化:充分利用TiDB的SQL優(yōu)化器(如CBO)和執(zhí)行計劃查看功能(
EXPLAIN)。對于復(fù)雜查詢,合理使用索引和TiFlash列存引擎是關(guān)鍵。 - 監(jiān)控與運維:善用TiDB Dashboard、Prometheus+Grafana等原生監(jiān)控工具,密切關(guān)注關(guān)鍵指標如QPS、延遲、存儲容量、Region健康度等,做到 proactive 運維。
###
TiDB通過其精巧的云原生分布式架構(gòu),將數(shù)據(jù)庫的擴展性、可用性與易用性提升到了一個新的高度。對于技術(shù)開發(fā)者而言,它不僅僅是一個數(shù)據(jù)庫替換選項,更是一種構(gòu)建現(xiàn)代化、面向未來的數(shù)據(jù)處理平臺的全新范式。將TiDB融入技術(shù)棧,能夠有效應(yīng)對數(shù)據(jù)量激增、業(yè)務(wù)復(fù)雜度提升和實時性要求嚴苛的挑戰(zhàn),讓團隊更專注于業(yè)務(wù)邏輯創(chuàng)新,而非底層數(shù)據(jù)基礎(chǔ)設(shè)施的維護。
如若轉(zhuǎn)載,請注明出處:http://www.zgbjx.cn/product/69.html
更新時間:2026-01-25 18:55:26